Vor einigen Jahren waren sie in aller (Informatiker-)Munde – die NoSQL-Datenbanken. Was ist von diesem Hype geblieben? In diesem Post möchte ich die heutige Rolle von NoSQL beschreiben anhand eines Vergleichs zwischen drei besonders häufigen Kandidaten: MongoDB, CouchDB und PostgreSQL. Moment, Postgres als NoSQL? Mehr dazu später.
Zur Rekapitulation – was heisst eigentlich NoSQL?

Slide: Mark Madsen, Foto: Edd Dumbill
Die Definition von NoSQL ist, wie oben belustigenderweise klar wird, fliessend. Aus meiner Sicht ist die zentrale Idee von NoSQL das Fallenlassen der rein tabellenorientierten Datenstruktur. Demzufolge steht NoSQL nicht im Gegensatz zu rDBMS – NoSQL-Datenbanken können selbstverständlich genauso relationale Daten beinhalten wie die klassischen tabellenorientierten Datenbanken (MySQL und Konsorten).
Ein wichtiger Aspekt ist dabei die Möglichkeit, effizient mit schemalosen Daten umzugehen. Wieso ist Schemalosigkeit ein wichtiges Thema?
1.) Schemalosigkeit ermöglicht mehr Flexibilität, Benutzeranforderungen gerecht zu werden. Beispielsweise wird so die Implementation von ‘Notizen’ zu einem bestimmten Datensatz trivial, inkl. eingefügter Listen, Tabellen und Tabellen von Listen von Tabellen.
2.) Schemalosigkeit ermöglicht rapide Anwendungsentwicklung – das Schema kann in weiteren Dokumenten definiert und in der Anwendungslogik umgesetzt werden, was später Änderungen des Schemas ohne kostspielige Datenmigration möglich macht. Für sich oft ändernde Anforderungen kann dies ein zentraler Vorteil sein.
Im folgenden einmal tabellarisch die aus meiner Sicht wichtigsten Unterschiede von drei oft genannten Datenbanksystemen:
Legende:
- Grün: Positive Eigenschaft [e]
- Gelb: Neutrale Eigenschaft [e]
- Orange: Leicht negative Eigenschaft [e]
- Rot: Negative Eigenschaft [e]
| PostgreSQL | MongoDB | CouchDB | |
| Datenstruktur (aus Benutzersicht) | Tabellen, JSON-Felder möglich | JSON-Dokumente, | JSON-Dokumente, |
| Sicherheit bei Modifikationen | In-Place, Transaktionen möglich | In-Place, keine Transaktionen | Append-Only |
| Unterstützt Beziehungen | Ja | Ja | Ja |
| Prädefinierte Queries für Schemalose Daten | Ja, SQL+JSON | Ja, MongoDB queries | Ja, Map/Reduce |
| Ad-hoc Queries für Schemalose Daten | Ja, SQL+JSON | Ja, MongoDB queries | Ja, langsam |
| Joins innerhalb der Querysprache | Ja | Nein [1] | Nein |
| Konsistenzverhalten | ACID auf Collection-Ebene | ACID auf Dokumentenebene | ACID auf Dokumentenebene |
| Replikation mit Servern [a] | Ja, read-only slaves (multi-master mit Plugin) | Ja, read-only slaves | Ja, voll verteilt (multi-master) |
| Replikation mit PCs [b] | Ja, Plugin notwendig [3] | Nein | Ja |
| Replikation mit Mobilgeräten [c] | Nein | Nein | Ja, CouchbaseLite |
| Partielle Replikation | Ja, Plugin notwendig | Nein | Ja, ‘Replication Filter’ |
| Lock-freies Backup während dem Betrieb | Nein | Nein | Ja |
| Sharding [d] auf DB-Ebene | Nein | Ja [5] | Ja [4] |
| Schreib-Performanz bis zu Konsistenz bei kleinen Clustern / tiefer Last | Hoch [6] | Hoch [6] | Tief [6] |
| Schreib-Performanz mit “Eventual Consistency” bei grossen Clustern / hoher Last | Hängt von Replikations-Plugins ab | Hoch, sofern genügend Replikationssets verwendet werden [8] | Hoch (gute “Schwache Skalierung” [7] mit Anzahl der Instanzen) |
| Schreib-Performanz bis zu Konsistenz bei grossen Clustern / hoher Last | Hängt von Replikations-Plugins ab | Tief (skaliert nicht) | Hoch (gute “Schwache Skalierung” [7] mit Anzahl der Instanzen) |
[a] x86-Computer, die stets online bleiben [b] x86-Computer, die nur sporadisch online sind [c] mobile Embedded-Systeme [d] Aufteilung der Daten auf mehrere Server [e] im Vergleich zu den anderen hier geprüften Datenbanksysteme
[1] http://docs.mongodb.org/ecosystem/tutorial/model-data-for-ruby-on-rails/ [2] http://docs.mongodb.org/master/core/write-operations-atomicity/ [3] https://wiki.postgresql.org/wiki/Warm_Standby [4] http://docs.couchdb.org/en/latest/cluster/sharding.html [5] http://docs.mongodb.org/manual/sharding/ [6] http://artur.ejsmont.org/blog/content/insert-performance-comparison-of-nosql-vs-sql-servers [7] http://www.simunova.com/de/node/188 [8] http://docs.mongodb.org/manual/replication/
Zusammenfassend können diese drei Datenbanksysteme folgendermassen charakterisiert werden: PostgreSQL: Hohe Flexibilität bei der verwendeten Datenstruktur, mächtige Queries und Transaktionen. MongoDB: Ein Kind, geboren im NoSQL-Fieber. CouchDB: Bedingungslose Zweiwege-Replikation überallhin.
CouchDB gewinnt die Flexibilität bei der Replikation durch “append-only”-Modifikationen (im Betrieb werden Datensätze nie überschrieben, stattdessen wird automatisch eine neue Version angehängt – alte Versionen werden nur bei Compact-Aktionen gelöscht).
Was MongoDB betrifft: Aufgrund der oben gezeigten Eigenschaften sind aus meiner Sicht die NoSQL-spezifischen Vorteile gegenüber PostgreSQL zu klein. Spätestens seit PostgreSQL in der Version 9.4 indexierbare JSONB-Felder hinzugefügt hat, kann diese SQL-Datenbank auch als voll funktionsfähiger Document-Store verwendet werden, jedoch mit besseren Konsistenzgarantien und Transaktions-Funktionalitäten gegenüber MongoDB. Falls diese Features egal sind und lediglich die Lese- / Schreibperformanz einzelner Einträge wichtig ist, empfehle ich stattdessen einen sogenannten Key-Value-Store (KVS) wie z.B. Redis. KVS sind grundsätzlich aufgrund des reduzierten Funktionsumfanges wesentlich einfacher zu optimieren und sind deshalb für einfache Anwendungen performanter.
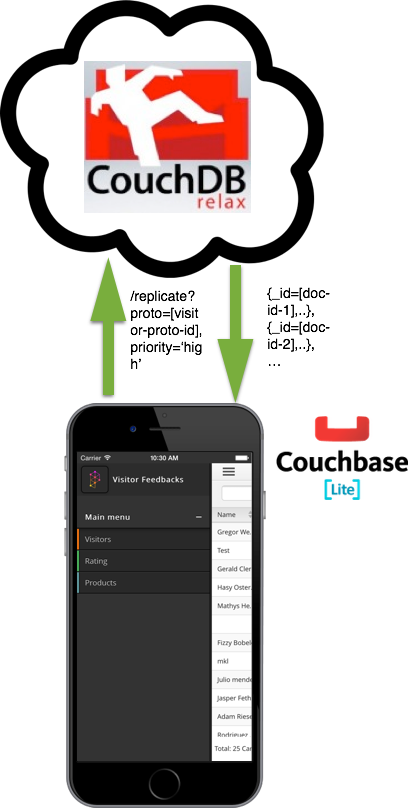
Gefilterte Replikation in CouchDB erlaubt es, die synchronisierten Daten zu priorisieren. Dies ist ideal, wenn die Bandbreite und/oder der Speicherplatz auf dem Gerät knapp ist.
Im 2012 stand ich mit meinem Team vor der Herausforderung, eine neue Software-Entwicklungsplattform namens “Protogrid” zu entwickeln, die mobile Geräte, hohe Portabilität, Rapid Application Development und Offline-Verfügbarkeit unterstützen muss (wir Schweizer haben viele Tunnels). Wir haben dabei zahlreiche Datenbanksysteme eingehend geprüft.
Schlussendlich war Flexibilität bei der Replikation ausschlaggebend, insbesondere auch für die Unterstützung von Mobilgeräten. Dies hat uns erlaubt, die Funktionalität von Protogrid 1-zu-1 auf mobile Platformen zu portieren, ohne den Entwicklungsaufwand zu vervielfachen. CouchDB war deshalb für dieses Produkt die offensichtliche Lösung. Ein hierbei besonders relevantes Feature sind die “Replication Filter”. Diese erlauben es, die synchronisierten Daten zu priorisieren – ideal wenn die Bandbreite und/oder der Speicherplatz auf dem Gerät knapp ist.
Offensichtlich gilt bei Datenbanken nach wie vor: “No size fits all”, d.h. eine Universallösung gibt es nicht. Da die Datenmigrationskosten zu einem späten Zeitpunkt beliebig hoch sein können, ist die Wahl der Datenbank während der Designphase eines Projekts entscheidend. Das Beispiel Protogrid zeigt: Die Wahl des korrekten DBMS hat es später möglich gemacht, die Integration des Produkts auf Mobilgeräte so einfach zu machen, dass fertige Applikationen innert Minuten und ohne Anpassungen ausgerollt werden können.
NoSQL ist insofern immer noch eine wichtige Philosophie, als dass Datenbankkonventionen einmal in Frage gestellt werden mussten, um den Wert von höherer Flexibilität bei der Datenstruktur zu erkennen – gerade auch die aktuellen Entwicklungen in der SQL-Welt zeigen, dass diese Flexibilität auch bei eingefuchsten SQL-Hasen einen gewissen Anklang gefunden hat. Für die Datenbankprogrammierer heisst dies heute: Die Auswahl ist grösser geworden und es lohnt sich, genau die Vor- und Nachteile der verschiedenen Paradigmen zu verstehen.


